
The RSE Framework
Most backend platform teams aren't building the wrong things. They're building in the wrong order. Roadmap, System, Ecosystem: the three-stage model for a platform that compounds.


The team had been building for eight months. Four tools shipped, two more in review. The platform lead was proud, and rightly so. The work was good. The code was clean. The internal docs were better than most external ones I’ve seen.
Nobody was using any of it.
Not because the tools were bad. Because the team had built them in the wrong sequence. They’d gone straight to System without doing Roadmap. They’d solved the problems they assumed product engineers had, rather than the ones product engineers were actually bleeding on that quarter. When adoption flatlined, they interpreted it as a distribution problem and wrote more documentation. It wasn’t a distribution problem. It was a sequencing problem, and no amount of docs fixes that.
I’ve seen this pattern more times than I can count. Teams that ship consistently but compound nothing. Teams that build in circles because they never established what “done” looks like for a platform problem. Teams that arrive at ecosystem thinking without the trust to back it up. The tools are real. The adoption isn’t. The platform exists on paper but not in behavior.
The RSE Framework is my attempt to name what’s actually happening. To give platform teams a sequential operating model that prevents the most common failure modes before they have a chance to take root.
I've also put together a free slide deck covering the full framework. Useful if you want something to reference or share with your team.
Platform teams don’t fail by building badly.
They fail by building out of order. That’s a harder problem to diagnose, because the output looks like progress. Tools ship. PRs merge. Demos happen. The team is busy. And yet six months later, the platform’s adoption curve is flat, the roadmap feels like a guessing game, and the engineering leader who funded the team is quietly asking whether it’s working.
This isn’t a resource problem. The teams I’ve seen fail had engineers, often good ones. It wasn’t a technology problem either. The tooling choices were reasonable. It was an ordering problem. They’d skipped a stage they didn’t know they were supposed to do, or rushed through it, and the consequences arrived six months later looking like something else entirely.
The default mental model for a platform team is wrong. Most people think of it as “a team that builds internal tools.” That framing is accurate but incomplete. It describes the output without describing the operating model. Without an operating model, the team optimizes locally, solving whatever’s loudest this sprint, instead of compounding leverage across time.
What’s missing is a theory of sequencing. What do you do first, what does it unlock, and what happens when you skip it? That question doesn’t have an obvious answer when you’re standing at the beginning. Most teams discover the answer the hard way, in retrospect, after the adoption plateau or the reorg.
RSE is my answer to that question. It’s not a methodology with ceremonies. It’s a three-stage progression: Roadmap, System, Ecosystem. Each stage builds the foundation the next one depends on. Skipping a stage produces a predictable, nameable failure mode.
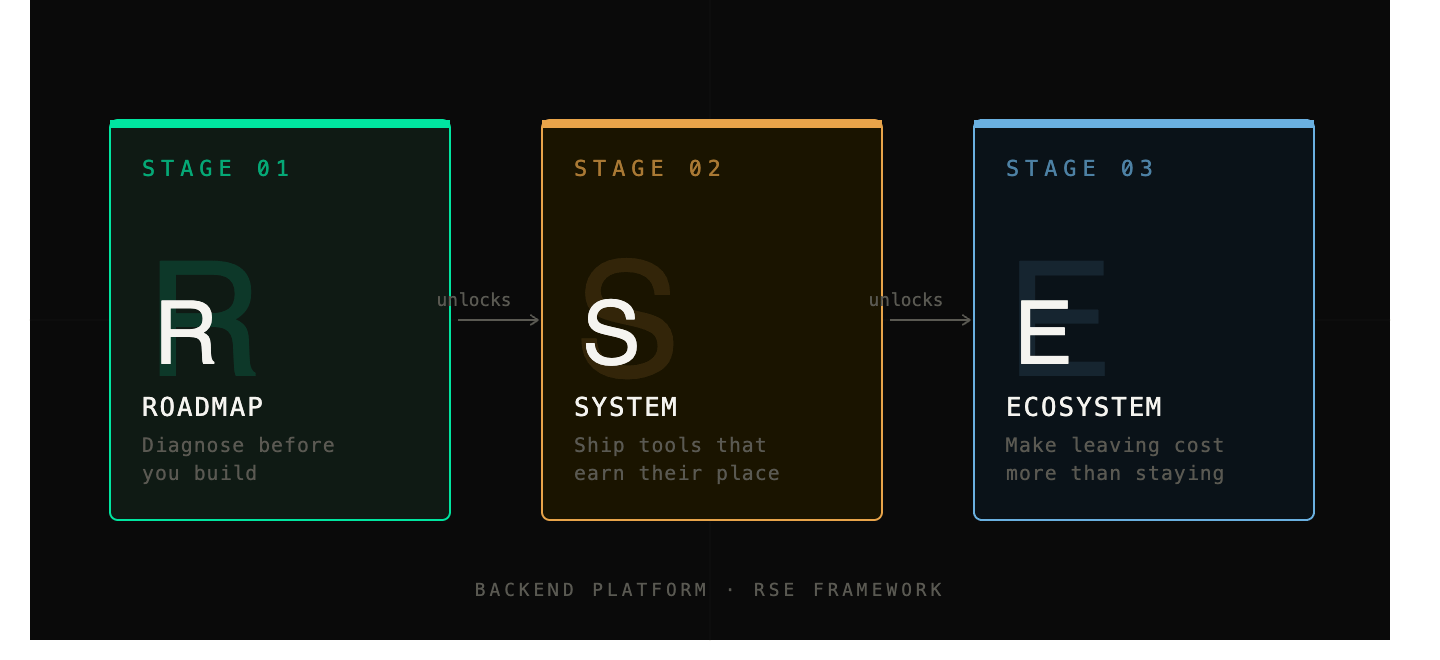
Before R, S, or E: The Two-Audience Discipline
Before explaining any of the three stages, there’s a meta-principle that threads through all of them. It’s the lens that RSE gets read through, and ignoring it is one of the fastest ways to build a platform team that’s technically productive and organizationally invisible.
Engineers are the customer. Leaders are the investor.
Engineers use the tools daily. Their adoption is the only real measure of whether the platform exists. If they route around you, nothing else matters. Not the docs, not the roadmap, not the OKRs.
Engineering leaders fund the team, defend its scope in headcount conversations, and decide whether it survives the next reorg. They don’t use the tools. They need to see the return.
Build only for engineers and you lose your funding. Build only for leaders and you lose your users. Both have to hold simultaneously, at every stage.
This split isn’t a communications strategy. It’s an architectural constraint. In Roadmap, problems are sourced from engineers (they feel the pain) but ranked in language leaders understand: hours recovered, incidents avoided, headcount-equivalent leverage. In System, tools are built for engineer ergonomics, but every one tracks a metric legible to someone writing a budget defense. In Ecosystem, adoption rate proves the customer hypothesis while cost-of-replacement proves the investor thesis.

What Skipping Stages Produces
The naive approach to platform team strategy is to start building whatever’s loudest. A product engineer complains about service scaffolding, so you build a scaffold starter. Another team mentions inconsistent observability, so you write a shared logging library. Each decision feels reasonable in isolation. The team is responding to real pain. But the sequencing is emergent and reactive rather than deliberate and compounding.
When I talk about “skipping a stage,” I don’t mean ignoring it entirely. I mean doing it incompletely, implicitly, or in the wrong order. The result is always one of three recognizable failure modes. These aren’t hypotheticals. They’re patterns I’ve seen play out at real teams, and the failure mode names itself once you know what to look for.

The interesting thing about these failure modes is that they’re each invisible from inside the team experiencing them. Roadmap-less building looks like thoroughness. System-less shipping looks like productivity. Ecosystem-less platforming looks like vision. They only become legible as failure modes in retrospect, or from the outside.

RSE: The Operating Model
Each stage has a clear purpose and an extractable principle. The stages are sequential. Each one builds the foundation the next depends on. But they’re not linear in the sprint-by-sprint sense. You’ll revisit Roadmap when your team grows or your org reorgs. You’ll refine System as adoption data comes in. The sequence is about what earns what, not about time boxes.
R: Roadmap
A ranked list of problems with explicit exit conditions. Not a list of tools.
That distinction sounds minor and is not. Most platform team “roadmaps” are actually lists of things someone wants to build. A proper Roadmap is a prioritized list of things that are wrong: problems, friction points, failure modes, each with a clear definition of what “solved” looks like. The tool that solves the problem comes later. The problem comes first.
You can’t build a system for problems you haven’t named. The Roadmap stage is where you earn the right to start building.
R.01: Problem Discovery
Pain surveys over whiteboards. The instinct, especially for strong engineers, is to synthesize the solution space, to think about what a well-run platform team should build and work backwards. That produces plausible-sounding roadmaps that nobody asked for.
The correct starting point is talking to product engineers about what cost them time last sprint. Not what they think a platform team should build, but what specifically made their work harder than it should have been. The questions the team isn’t asking are often the problems the platform should solve. What’s too painful to even put on a ticket? What do engineers work around rather than fix?
R.02: Prioritization
Once you have the problem list, you rank it:
frequency x severity x blast radius
How often does this problem occur, how bad is each occurrence, and how many teams does it affect? Multiply those three scores. The top three problems are your P0s. Everything else is a distraction until those ship.
Prioritization is also where the Two-Audience discipline shows up most directly. Engineers feel the pain in ways that map naturally to frequency and severity. Blast radius is the investor framing: it’s what makes the problem legible at a headcount conversation. A problem that affects eight teams is a different budget conversation than a problem that affects one. The ranking must be defensible to both audiences.
R.03: Scope Definition
The charter. Five sections: mission, scope, non-scope, SRE boundary contract, KPIs. If you can’t write it in two pages, the team doesn’t exist yet. It’s a group of engineers with overlapping tickets and a shared Slack channel.
The non-scope section is as important as the scope section. Without an explicit boundary, platform teams accumulate operational burden. A charter with a clear non-scope makes “no” a policy decision rather than a personal one. That’s the only way to hold the boundary when leadership is watching.
The SRE boundary contract deserves specific attention. The line between backend platform engineering and infrastructure/SRE is genuinely blurry, and without a written agreement it becomes a source of chronic territorial friction. Which pager rotation does a given tool live in? Who owns the SLA? Who handles migrations? Write it down.
R.04: Sequencing
Which problems unlock the next ones. Solve scaffolding before observability, because observability rides on scaffolding. Solve config before feature flags, because flags depend on config. The dependency graph of your problems is as real as the dependency graph of your code. It determines what order operations have to happen in.
R.05: Success Criteria
Define what “solved” looks like before you start. If you don’t define done before you begin, done becomes “the tool shipped,” and that’s not the same thing.
Success criteria live at two levels: customer-facing (adoption rate per eligible service, steps removed, time-to-production for a new consumer) and investor-facing (developer hours recovered per quarter, incidents avoided, headcount-equivalent leverage). Both sets need to be defined upfront, tracked explicitly, and reported on. A tool ships against both or it doesn’t ship.
A roadmap isn’t a list of tools. It’s a ranked list of problems with explicit exit conditions, defensible to the engineers bleeding on them and to the people writing the checks.
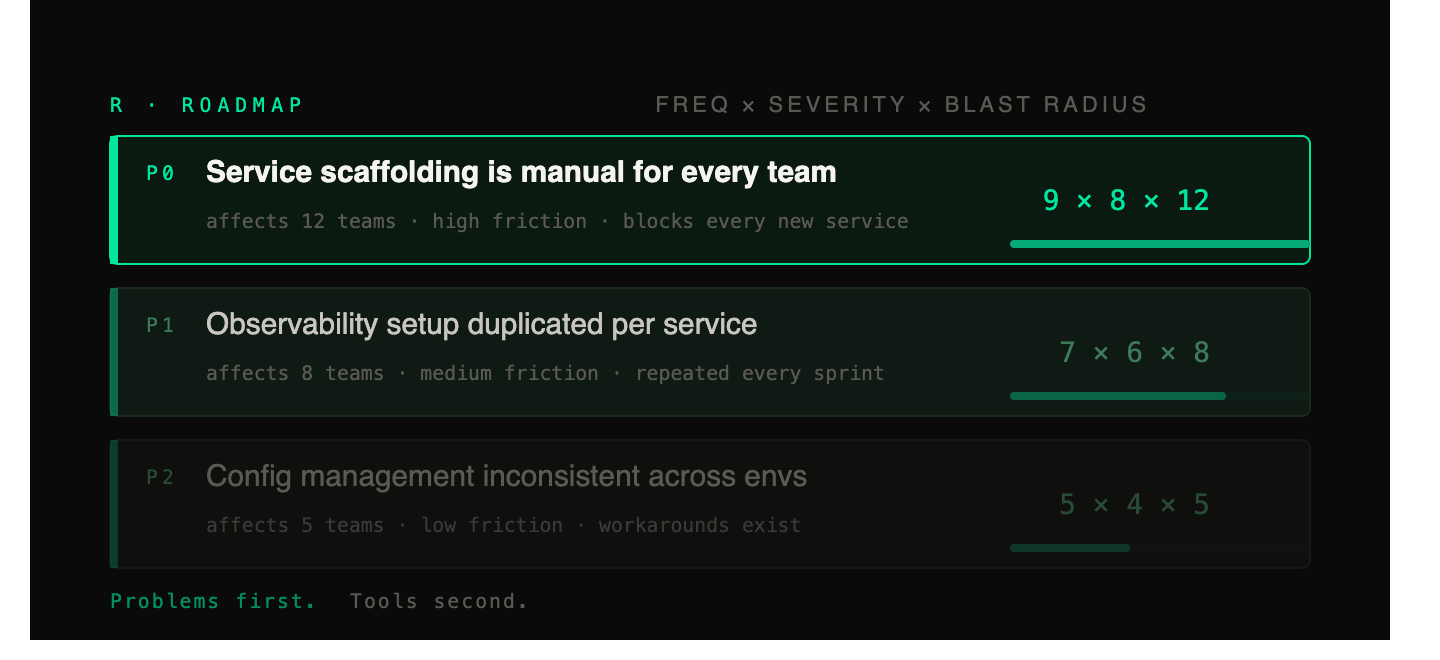
S: System
The execution playbook that turns named problems into tools that compound rather than one-offs that decay.
Most teams fail here. Not by shipping badly, but by shipping without a system. Each tool is built from scratch in terms of quality bar, distribution strategy, documentation approach, and versioning discipline. The tenth tool has no more adoption momentum than the first. Nothing compounds because nothing was designed to compound.
The System stage is about building each tool so that the next one is easier to build, easier to adopt, and harder to replace.
A tool that ships once is a feature. A tool that gets adopted, versioned, documented, and depended on is a platform asset. The System is what turns the first into the second.
S.01: Compile-Time First
Bias toward libraries, starters, and annotations over runtime services. Every new internal runtime service is a new on-call rotation, a new SLA, a new blast radius. When that service has an incident at 2am, it’s your team’s pager. Compile-time dependencies fail gracefully. Runtime ones page you.
Runtime services are sometimes necessary. But they should be last resorts, not defaults. If the same problem can be solved at compile time, solve it there.
S.02: The Wrapper Test
Before any tool ships, it has to clear three questions. Does it lower implementation time, as in hours genuinely saved per service? Does it improve developer experience, meaning steps removed, errors prevented at compile time, defaults that actually work? Does it provide an operational benefit the engineer couldn’t get themselves, like observability wired in, retries handled, idempotency enforced by default?
A wrapper that does what the underlying library already does isn’t a platform asset. It’s tax with your team’s name on it.
S.03: Documentation as First-Class
A tool isn’t done when the code merges. It’s done when an engineer who’s never seen it can go from “I need this” to “it’s in production” without messaging the platform team.
That means a working quickstart that runs end-to-end in under ten minutes, a failure-mode reference that answers the three questions engineers ask most often, and versioned docs with visible deprecation timelines. Undocumented tools don’t get adopted. They get tolerated until something better appears.
S.04: Paved Road, Not Mandate
The default path has to be the easiest path. If using the platform tool is harder than rolling their own, product teams roll their own. Mandates fail against friction. Friction beats mandates every time. The goal is to make the right thing the path of least resistance, the thing a new engineer does without being told to.
S.05: Distribution Mechanics
Adoption isn’t a launch problem. The most effective strategy: embed with one product team per sprint. Solve their specific, named pain. Let them become advocates. When that engineer talks to another team about how they solved the problem, it carries infinitely more weight than anything the platform team announces internally. Internal announcement emails don’t move adoption. Respected product engineers do.
S.06: Versioning and Migration Discipline
Plan v2 before v1 launches. The deprecation path is part of the initial design, not an afterthought. Platform team credibility is built on how it handles upgrades, not how it handles launches. A migration that’s smooth and well-communicated earns more goodwill than a polished launch. A painful migration destroys the credibility that a dozen launches built up.
S.07: Observability of the Platform Itself
Your tools need their own metrics. Adoption rate per eligible service. Error rate per consumer. Developer time saved, measured and reported. You can’t compound what you can’t measure, and you can’t defend a platform budget on vibes.
S.08: The Reactive/Planned Split
Protect planned work from reactive support. A standard split worth defending: 60% planned tooling, 30% reactive support, 10% tech debt. Without this split, reactive work eats everything and the roadmap becomes fiction. This is a leadership-level decision, not a sprint negotiation. If it’s left to the team to self-enforce, reactive work wins by default.
A tool that ships once is a feature. A tool that gets adopted, versioned, documented, and depended on is a platform asset. The System is what turns the first into the second.
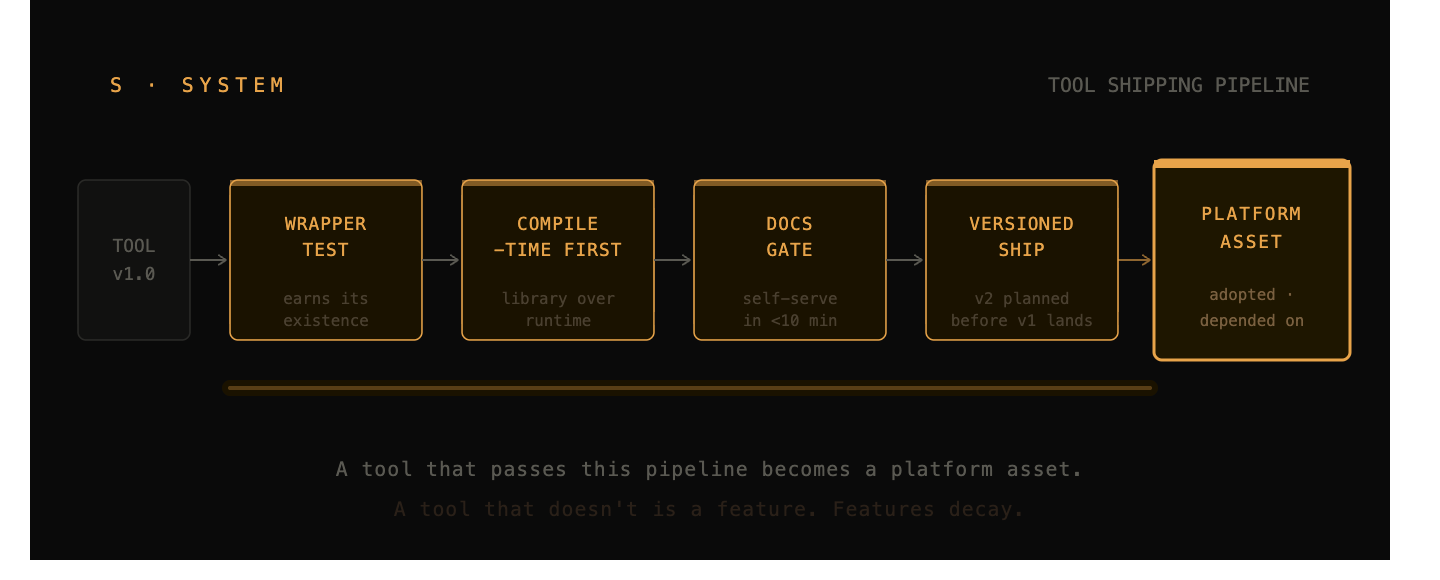
E: Ecosystem
Individual tools are replaceable. An ecosystem is not.
The Ecosystem stage is where a team that ships good tools becomes a team that is infrastructure. It’s the phase where the platform stops being a service product teams use and starts being the environment they work inside. That shift doesn’t happen by accident. It happens because the System stage was executed with compounding as a design goal.
An ecosystem isn’t tools that coexist. It’s tools that make each other more valuable, to the point where leaving the ecosystem costs more than building inside it.
E.01: Interoperability by Default
Every tool in the ecosystem speaks to every other one. The starter ships with logging, tracing, metrics, auth, and feature flags wired in. Pulling one piece means losing all of them, intentionally. Standalone tools don’t compound. Interoperable tools do.
E.02: Shared Primitives
One auth model. One config system. One error taxonomy. One observability schema. Product engineers learn it once and it applies everywhere. The primitives are what make the ecosystem feel like a single product instead of a collection of utilities with inconsistent interfaces, and what makes onboarding fast at scale.
E.03: The Golden Path
A single documented sequence from “I have an idea” to “I’m in production with audit logging, idempotency, and dashboards.” The default is mandatory. The escape hatch is opt-in but supported.
The golden path is a contract, not a cage. Every tool on the path ships with documented extension points: interfaces to implement, hooks to override, config to swap. No tool is allowed to be a black box. A team with a legitimate edge case can get off the path, but they do it explicitly and they lose the platform team’s SLA in doing so. Anything outside the golden path is a one-off the platform team doesn’t owe support to.
E.04: Compounding Surface Area
Every new tool that integrates with existing ones makes the existing ones more valuable. The third tool in an ecosystem is worth more than the first three standalone tools combined. Compounding is the design goal, not feature breadth, not tool count.
The metric that proves this to leadership: not “we shipped six tools this quarter” but “adding the sixth tool increased average daily active usage of the first five.” That’s compounding.
E.05: Cultural Lock-In
When senior engineers refuse to onboard at companies without an internal platform like yours, you’ve won. The ecosystem isn’t the tools. It’s the expectation engineers have about how their work should feel. That expectation is the most durable moat a platform team can build, and it can’t be copied by writing a single tool.
Cultural lock-in isn’t manipulative. It’s the natural result of building tools engineers genuinely prefer. The lock-in is just the cost-benefit math coming out in the platform’s favor consistently enough that it becomes the default assumption.
E.06: External Boundary
What the ecosystem deliberately does not cover. Product logic stays with product teams. The ecosystem owns the layer underneath, not the layer above. Without an enforced boundary, the platform becomes a dumping ground for everything nobody else wants, and it dies under the weight of work it never should have owned.
An ecosystem isn’t tools that coexist. It’s tools that make each other more valuable, to the point where leaving the ecosystem costs more than building inside it.
The Sequencing Is Not Optional
I want to be explicit about what I’m arguing here, because RSE can be read as three helpful categories that you can mix and match. That reading is wrong.
The sequencing matters. You cannot do System well without Roadmap, because System executed without Roadmap is system-less shipping and you won’t know it until adoption flatlines. You cannot do Ecosystem well without System, because Ecosystem without System is architecture astronautics and the org will reorganize before you earn the trust to back it up.
R before S before E is a constraint, not a preference.
The legitimate objection is: “We’re already in S or E, does this framework help us at all?” It does, but differently.
If you’re in System without having done Roadmap properly, the immediate move is a discovery pass. Not to restart, but to validate that what you’re currently building maps to the problems product engineers are actually experiencing. Run the pain survey. Check the frequency x severity x blast radius ranking against your current tool priorities. If they’re misaligned, adjust.
If you’re in Ecosystem without System discipline, meaning you’re designing for interoperability and shared primitives but the tools themselves don’t pass the Wrapper Test, pull back. The ecosystem design is aspirationally correct but operationally premature. Earn System credibility first. Then the ecosystem becomes achievable rather than theoretical.
Most backend platform teams aren’t building the wrong things. They’re building in the wrong order. Roadmap before System, System before Ecosystem. The sequencing is the strategy.
The Maturity Arc as a Field Diagnosis
Once you have the RSE model, you can use it to diagnose where any platform team is, including your own, and what’s blocking them from moving to the next stage.
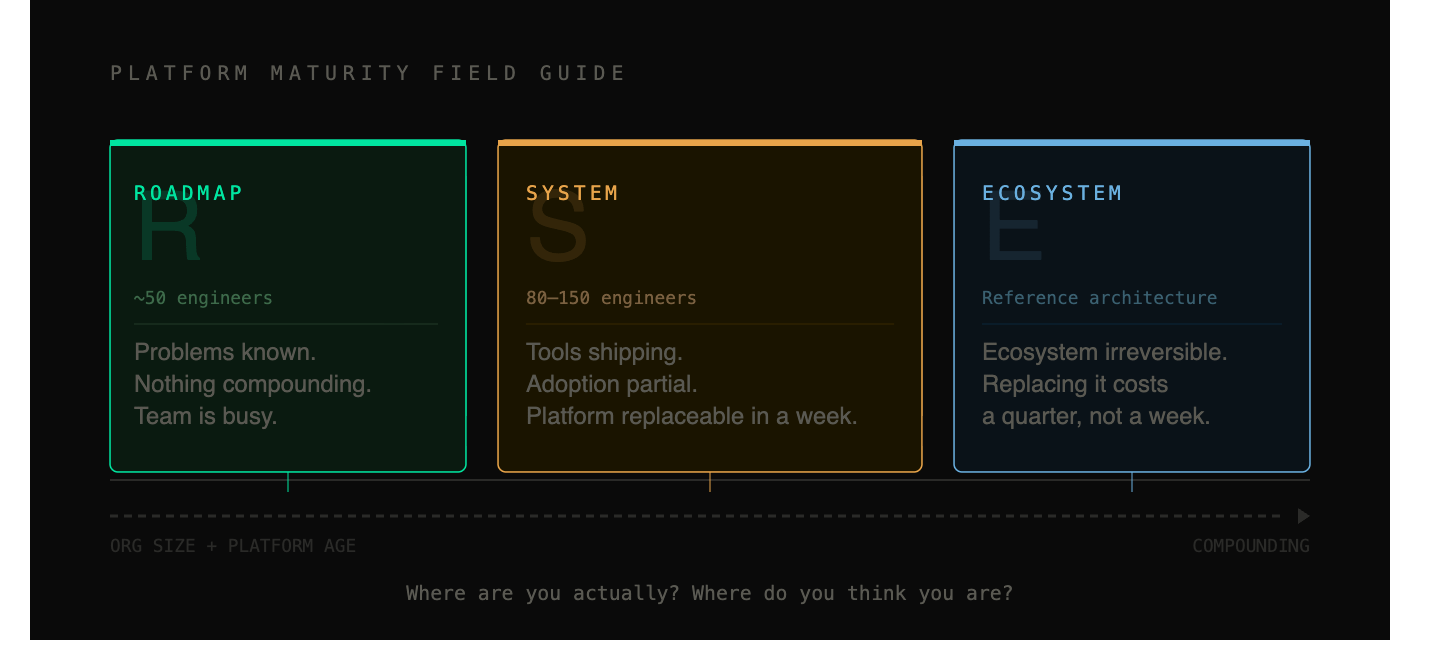
Most fifty-engineer organizations are stuck in R. They know the problems exist. They can name them. They haven’t ranked them, chartered the team to own them, or defined what “solved” looks like. The team is busy, the roadmap exists, and nothing is compounding.
Most organizations between eighty and one hundred fifty engineers have an S but no E. They ship tools. The tools work. Adoption is partial: teams close to the platform team use the tools, teams furthest away roll their own. Each tool stands alone. Removing the platform would cost a week of refactoring, not a quarter. The investment is real but not yet irreversible.
The teams that reach E are the ones that became reference architectures. The ones where senior engineers talk about “how we do things here” with a specificity and coherence that reveals an underlying system. The ones where a new service scaffolds in ten minutes and ships with audit logging, idempotency, and dashboards wired in, because that’s just how things work here.
The Question Only Your Context Can Answer
The extractable principle from RSE is simple enough to write on a whiteboard:
Roadmap earns the right to build. System earns the right to compound. Ecosystem earns the right to become infrastructure.
Skip a stage and you skip what that stage earns. The failure mode that follows isn’t punishment. It’s just physics. Systems that skip foundations don’t compound; they accumulate.
Look at your current platform work and ask honestly: which stage are you actually in, and which stage do you think you’re in? If those are the same answer, you’re ahead of most. If there’s a gap between them, that gap is the thing worth fixing before you build anything else.
What would change about your team’s next sprint if you took the RSE sequencing seriously, not as a framework to understand, but as a constraint to build inside?